I got accepted to CXL institutes’ conversion optimisation mini-degree scholarship. It claims to be one of the most thorough conversion rate optimisation training programs in the world. The program runs online and covers 74 hours and 37h minutes of content over 12 weeks. As part of the scholarship, I have to write an essay about what I learn each week. This is my eight report.

This post will show you how to build a repeatable usability test for a digital product. This test is designed to be performed remotely and is to be conducted with new users (as opposed to existing users). Usability testing can be a valuable diagnostic tool to objectively understand and quantify points of friction in a product.
Quantifying the customer experience is helpful for two reasons. The first benefit is that it encourages meaningful conversation. When you quantify how usable something is then everyone can see that this bit of the product is harder to use than this other bit.
The second benefit of quantification is that it gives you a baseline . This lets you track the impact changes are having to your product over time.
First Find 10 People#
You will need a minimum of 10 people to run a test. 20 people is ideal because the results will stabilize and you’re left with a more reliable baseline. 10 people is the absolute minimum though.
If you product has different types of users, like drivers and riders, you will need to run two tests, each with 10 users.
The 10 people you find must be part of your target audience. If your product is for octogenarians and you test it with 10 high school students the results will be misleading.
You will be performing the test on a single device. If you want usability scores for desktop, tablet and mobile, you will need to run three separate tests.
I use a tool called TrymyUI for my remote usability testing. It lets you select the demographic you want and then it finds people for you and schedules the tests. If your target audience is more specific you can use Respondent to find the people you need (links to both are in the footer). These are both paid tools.
If you’re recruiting people you know then reach out to them directly and schedule a video call with screen share. I prefer an automated approach because you are not there to bias the test and people use your app in an unsupervised way that better resembles the way they would use it in real life.
Then Decide On Your Top 10 Tasks#
In order to run a user test you have to give people clear tasks to complete when they are using your application.
The goal is to narrow in on the ten most important tasks to experience the value your product has to offer. You can only do 10 tasks because people have limited attention. 15 minutes is ideal, if a test goes on for more than 30 minutes people get impatient and the results will show you that people want to end the test (rather than that your app is hard to use).
These questions can be the greatest source of noise in this process so it is important that you word them clearly and correctly.
The goal here is to describe the end result not the process. “Create a new blog post with the following title…” is a much better ask than “click on the ‘Create Blog Post’ button and then select X before adding Y to Z”. Your button text and process might change over time but the thing you are helping them achieve stays the same. Phrase the questions so that you can repeat the test again in 6 to 12 months, regardless of interface changes.
Don’t make the task questions difficult. The idea is to start off with reasonably basic questions that everyone can do. Keep the tasks to 30 words or less and make sure there are not hints embedded in the question.
Each task should have one objectively correct outcome. When a task is complete you want to be able to ask them how confident they were doing the tasks. You want to be able to compare this confidence rating to whether or not they actually completed the task correctly. So “Change your username from X to Y and then return to the articles page” is a much better task than “Update your settings”.
If you are doing a test manually then you will need to give each instruction in succession. Wait for them to finish the task and then ask them how confident they are that they completed the task correctly (on a scale of 1 to 7). If you are using a remote testing platform then you add the tasks to the system, they get presented to the user sequentially and the user is asked for a confidence rating at the end of each task.
Calculate The Scores#
The usability score for a task is calculated by taking the average confidence rating for all successfully completed tasks (as a percentage) and dividing it by the percentage of people who successfully completed the task. Don’t worry, I will unpack that.
Here are the results from an actual user test I ran. The descriptions of the tasks and the names of the people have been changed to keep this anonymous.
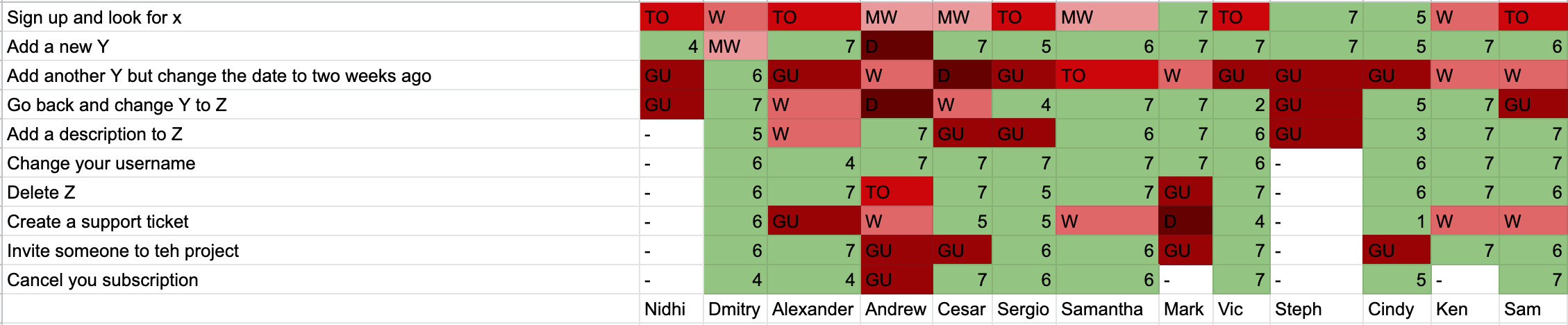
The green blocks denotes successfully completed tasks. You need to work out a reasonable time for each task. If people successfully complete the task within that timeframe then you ask then how confident they are that they completed the task correctly (on a scale of 1-low to 7-high) and add their score in a green box.
- TO: If the person completed the task correctly but took longer than the maximum time allocated then you mark it as Timed Out (TO).
- MW: If the person is unsure that they got the task right, or if their answer is almost correct then mark it as a minor wrong (MW).
- W: If the person completed the task incorrectly and they know they got it wrong then it gets marked as wrong (W).
- GU: When someone can’t figure out how to complete the task then mark that they gave up (GU).
- D: The worst thing that can happen is when someone completes a task, and is confident they completed the task correctly, but they actually got it wrong. This is marked as a disaster(D).
To calculate the average confidence rating you add up all the users confidence ratings for a successfully completed task and divide it by the total number of completed tasks. So in the screenshot above, if you look at row 1, you will see that only 3 people completed the task correctly (Mark, Steph and Cindy). If you average their confidence scores (7,7,5) you get 6.33. To represent this as a percentage you divide by 7 which give you 90%.
Then you need to work out the percentage of people who successfully completed the task. 13 people attempted the task in row 1, only 3 completed it successfully, so that 23.08%.
To calculate your usability score you multiply the average confidence by the percentage completed the task. In this case we get 21% (which is 23% x 90%).
It is important to work out the percentage completed because in some cases people don’t always begin the task. This can happen when people take too long in preceding tasks and the test ends at the 30 minute mark. Other times it is because people botch a dependant task. For example, if you look at Steph’s column she gave up on three tasks in a row, at which point the 6th task didn’t make any sense. If the first task was to create a blog post and they can’t figure out how to to do it, the next task of editing that same blog post won’t make any sense.
Analyze The Results#
If you repeat the calculation for each of your tasks you will end up with a average usability score for each of your 10 core tasks.
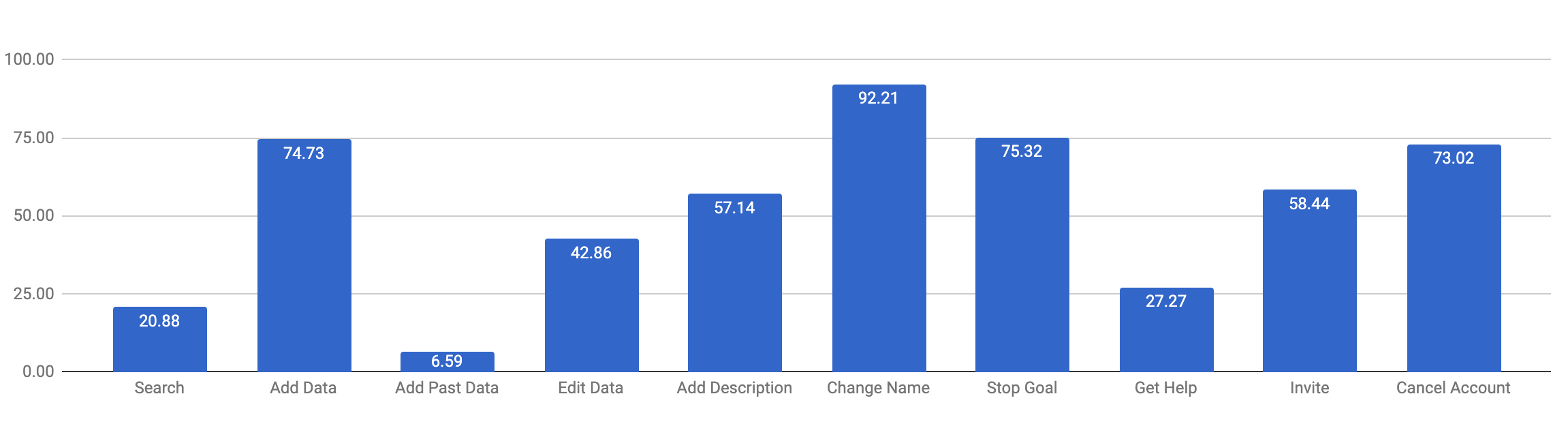
This graph instantly shows you where you need to pay the most attention: Task 1, 3 and 8 were clearly the hardest to complete.
Working on improving these tasks first will have the most dramatic effect on your overall usability score (which you can work out by average out all the scores, so 52.85% in this case).
You can then go back to a specific task and look for the patterns behind the poor performance. Were people giving up? Were the mistakes disasterous?Are there just minor wrongs that need to be addressed?
It is tempting to forget that these numbers represent actual human beings. That is one of the biggest problems when quantify things. This is when you go back and watch video recordings of real people grappling with specific points of failure so that you can understand and empathise with what happened.
This approach to user testing is useful because it is repeatable. If you do the test twice, without making any changes to the product, you will get roughly the same result. If there is a lot of variance between users then you need a larger sample size (20 people is typically enough). 10 people is usually enough if there is not a lot of variance between participants. We’re not talking about exact reproducibility down to the decimal point. Rather it is a stable and reliable metric, that is repeatable enough over time to be a useful measure. If a task performs at 30% one quarter and then it comes out at 60% 3 months later, you can be confident that the changes you made had a positive impact (provided that you have not changed the test questions).
Remember that usability is necessary but not sufficient for a great product. Quantification can lure you into thinking that when you have 100% on all of your tasks that your job is done. This is not the case. The questions we are asking is whether or not people can complete the task then came to do? If they can’t then you have a problem you need to fix. Just because someone can use something doesn’t mean they will begin using it religiously and start raving about how amazing it is.
Links#
- TryMyUI is the platform I use for user testing. I am not affiliated in anyway. there are definitely other platforms you can use, this is just the one I am most comfortable with. It is a paid tool.
- Respondent is a tool that you can use for recruiting test participants. It is a paid tool.
- The idea for this whole approach came from a fantastic article by Gerry McGovern called Task Performance Indicator: A Management Metric for Customer Experience.
- If you’d like to read more posts about conversion optimisation you can follow me on twitter @joshpitzalis.
- This is post 8 in a series. The rest of the posts are listed here.
- This is the CXL Institute’s conversion rate optimisation program I am currently doing.